Hello, I'm
SathyapalReddy.
AI Data Engineer building production data pipelines that ship intelligence — from FDA regulatory AI to large-scale clinical ML on Databricks. MS Data Analytics Engineering at George Mason University. Open to AI Data Engineer roles.
Sathyapal Reddy
AI Data Engineer
George Mason University
Fairfax, Virginia 22030
Building the intersection of
Data & AI Engineering
I'm an AI Data Engineer who builds production-grade data systems that ship intelligence — not just dashboards. I design end-to-end pipelines on AWS and Databricks, then layer LLMs, RAG, and ML models on top so data actually drives decisions.
Proven impact at scale: reduced API latency by 40%, supported a 200% increase in query throughput at Virtusa, and built an FDA regulatory AI platform (OCR, RAG, LangChain, python-docx) deployed via Docker Compose + Coolify for Precise Software Solutions.
Cloud-Scale Data Engineering
AWS, Databricks, Snowflake, PySpark, Kafka
GenAI & ML Integration
LangChain, RAG, FAISS, BERT, LightGBM
End-to-End AI Pipelines
FastAPI, OCR, python-docx, CI/CD
Technical Expertise
A production-tested toolkit spanning cloud data engineering, GenAI, and end-to-end ML.
Cloud & Data Engineering
AI / ML & GenAI
Databases & Modeling
Languages & Backend
DevOps & Tooling
Professional Journey
AI Data Engineer
Precise Software Solutions, Inc.
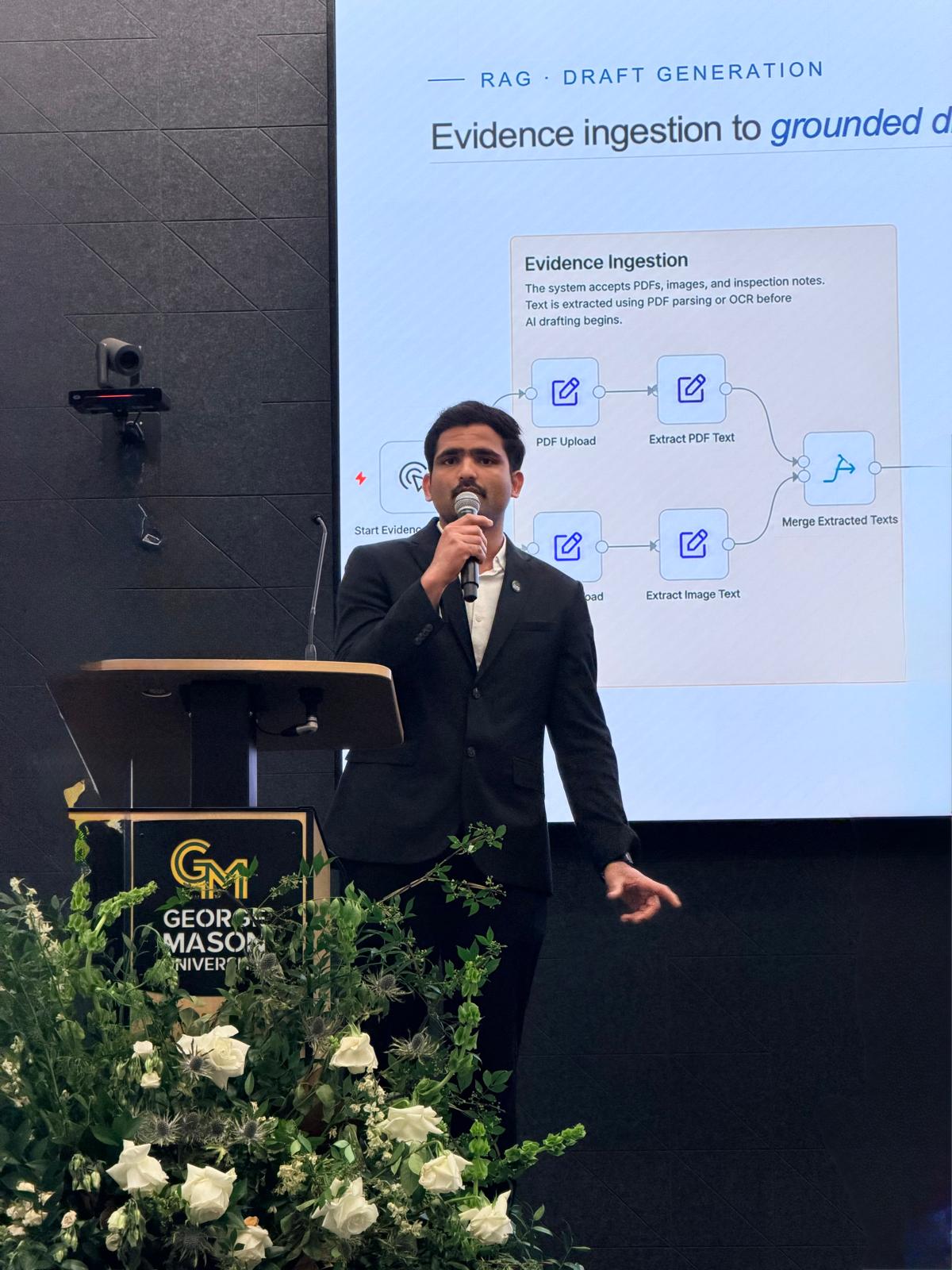
- ▸Built an end-to-end AI-assisted FDA Form 483 drafting platform — full-stack Docker Compose deployment (NGINX + Next.js + FastAPI) on a Hostinger VPS via Coolify, with Supabase PostgreSQL as the shared database.
- ▸Implemented OCR pipeline (PyMuPDF + Tesseract) for handwritten and typed notes; integrated LangChain + Google Gemini to generate draft observations with 21 CFR citations and evidence.
- ▸Designed a RAG (Retrieval-Augmented Generation) system over FDA guidance PDFs using FAISS vector search, plus a Title 21 CFR citation service for matching and validating regulatory references.
- ▸Shipped a document-generation pipeline (python-docx) producing FDA Form 483 and EIR .docx files in official format; deployed via Coolify with GitHub Actions CI and NGINX reverse proxy.
Data Engineer Intern
Virtusa
- ▸Scaled real-time data processing pipelines with Scala, AWS Lambda, Apache Spark, and Kafka — supporting a 200% increase in SQL Server query throughput for user-acquisition tracking.
- ▸Migrated on-prem databases to AWS RDS Multi-AZ with high-availability data modeling; used statistical analysis of system metrics to drive performance and uptime for critical growth operations.
- ▸Optimized SQL performance via advanced indexing and query restructuring; monitored with AWS CloudWatch — cutting API latency by 40%and accelerating product development cycles.
- ▸Automated infrastructure with AWS Step Functions, EMR, and Terraform; configured MongoDB and A/B-experiment analysis frameworks within data pipelines to validate model accuracy and data integrity.
Production AI Data Systems
End-to-end AI data platforms — regulatory NLP, clinical ML on Spark, and document intelligence.
Smart Inspections
Precise Software Solutions, Inc.
End-to-end AI-assisted FDA Form 483 & EIR drafting platform — OCR (PyMuPDF, Tesseract) for handwritten + typed inspection notes, LangChain + Google Gemini for draft generation with 21 CFR citations, RAG over FDA guidance PDFs (FAISS), and python-docx generation matching official format. Full-stack Docker Compose (NGINX + Next.js + FastAPI) deployed on Hostinger VPS via Coolify; Supabase PostgreSQL as the shared database.
ReadmitAI
Diabetes hospital-readmission prediction at scale — processed 101,766 inpatient records on Databricks + AWS EMR with PySpark (ICD-9 grouping, patient-level splitting, imputation, scaling, SMOTE). Trained Logistic Regression, Random Forest, XGBoost, and LightGBM; deployed the winning LightGBM model via CI/CD to AWS Lambda for real-time risk stratification. SHAP explainability surfaces top clinical predictors.
DocIE
Modular document-intelligence pipeline combining fine-tuned spaCy, ELECTRA (NER), and BERT (Relation Extraction) for structured information extraction from long documents. Integrated LLaMA-3.3 via Groq API with few-shot prompting for cross-section entity linking, plus RoBERTa-SQuAD2.0 QA for semantic search. Interactive Streamlit UI for real-time ingestion.
Academic Publications
Research Publication in Engineering & Technology
Sathyapal Reddy Peddakkagari et al.
Published in IRJET — a peer-reviewed international journal covering engineering, technology, and applied sciences. Represents undergraduate research completed during B.Tech at Institute of Aeronautical Engineering.
Research & Collaborations
A visual tour of my projects, publication and industry collaborations. Tap any card for the full story.
Degrees & Education
George Mason University
Fairfax, Virginia, USA
M.S. Data Analytics Engineering
Aug 2024 — May 2026
Institute of Aeronautical Engineering
Hyderabad, India
B.Tech Computer Engineering
Aug 2019 — May 2023
Relevant Coursework


Let's Build
the Next AI Data Platform
Open to AI Data Engineer roles — building production data pipelines on AWS and Databricks, then layering LLMs, RAG, and ML to turn data into shipped intelligence. Let's connect.